The Captcha
VNExpress, Chungta.vn, ngoisao.net, they’re all using a simple Captcha system to prevent bot voting/submit email. But unfortunately, the system is so easy, we can get around it in five minutes. (So, the voting poll, and all the competition based on voting in VNExpress is useless)
Recently, chungta.vn announced a new beta site with new design. Let’s take a look into it to know, if the internal is still the same.
Every site has a contact us form: http://beta.chungta.vn/contactus, and let’s face it, from the look, this captcha is so easy to crack: 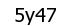
So, it seems that they generate an ID from the server side, generate an image and send back that ID and image to the client. The form have an hidden input with the id, and when you press submit, it will just send back the id in “captchaID” and the input text with “txtCode”
Problem: you can request the image multiple times.
For most Captcha systems, you can request the image only once. The next time you request the image, it will be replaced by another text. It’s an surprisingly easy way to make the life harder for some basic bots (although not that hard).
So you can download the file, store it somewhere, use OCR on it, do some other transformation, and compare the result. If it does not give a acceptable accurate answer, I can just request another (and do it cheap). They are generous enough to give me a link to do it: http://beta.chungta.vn/captcha/show2
Break it with Python and Google Tesseract
Google Tesseract is a very popular OCR engine, with a very accurate result. Combined with Python (because I know it) and PIL, you can do a lot of different thing with it.
Install everything is easy, if you’re using Windows, just download tesseract, python and PIL pre-built binary file (aka .exe) and install. If you’re using Linux, install it with your package manager:
$sudo apt-get install tesseract-ocr
$pip install pytesseract
$pip install pillowSo what do we have to do? First we get a captcha with the above link, the response is just a json text file. Then we extract the image id, the image above has id:“22b3fefb9d316f98489085252bd0d896”. Then we download the image by append the id to the url: “http://beta.chungta.vn/captcha/viewimg/id/". And last, some magic:
from PIL import Image
import pytesseract
print pytesseract.image_to_string(Image.open('captcha.png'))and the result is: ‘5y47’
Wait, is it that simple?
It is, it showed how ridiculous easy the captcha is. Now we just need to pre-fill the POST data with the id and captcha text, and also the mail content, and what left to do is automated-contact-us-spam-bot.
VNExpress’ captcha is a little harder, you will need to pre-process the image. How? I will give a hint:
after using Image.open to open the file, you have to:
- First, convert the image to RGB, then load the image into an array:
img = Image.open('captcha.png')
img = img.convert('RGB')
data = img.load()- Then, we flip the color for each pixel: set black for color blacker than a little black, and white for others.
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if data[x,y] should be black:
data[x,y] = (0, 0, 0, 255)
if data[x,y] should be white:
data[x,y] = (255, 255, 255, 255)
# and save
img.save("output.png")
And then you can just use pytesseract’s image_to_string. Sometimes I have to scale the image, and then do a simple anti-alias. But if you implement a good brute-force bot, you can just retry a few times, because the success rate is high.
I’ll leave the rest for your imagination. You can send a few thousand contact emails to say hello, or do some voting manipulation for science.