So, previously I wrote about breaking Chungta.vn’s captcha with Tesseract. At the end of the post I also mentioned about the pre-processing the image. And recently I found that they added some noisy lines over the text. This is the perfect time to talk about that part.
Disclaimer: I did contact and advised them to use a better captcha library or Google’s reCaptcha, I saw they use it a few times and then they just went back to this horrible captcha implement.
Let’s take a look at the new captcha: 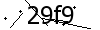 . I took it from http://chungta.vn/tin-tuc/nguoi-fpt/binh-chon-lanh-dao-cua-nam-2016-54844.html. They added some line and plus sign to make it harder for OCR to detect. Unfortunately this is also easy to bypass.
. I took it from http://chungta.vn/tin-tuc/nguoi-fpt/binh-chon-lanh-dao-cua-nam-2016-54844.html. They added some line and plus sign to make it harder for OCR to detect. Unfortunately this is also easy to bypass.
First, we do the usual stuff: open the image, convert it to black and white. But this time I upscale it with Image’s average algorithm to make it easier to process.
from PIL import Image
image = Image.open(sys.argv[2]).convert('L')
w, h = image.size
factor = 3
w = w * factor
h = h * factor
image = image.resize((w, h), Image.BOX)
img = image.load()1. Remove the small line
First trick is to remove the small line in the image. Most of the time the added lines are small, so we can scan all the pixel and for each pixel, find the number of continuous black pixel. If this number smaller than a threshold, we replace it with white color. And this is also why I upscaled the image.
This works surprisingly good with most type of captcha. If the captcha’s noisy line is bigger, it will be hard to read, so 99% of the time it’s small. Here the code for the row, the columns is the same, just flip x and y
for y in range(h):
for x in range(w):
if img[x, y] > 128: # white pixel
continue
total_black = 0
for c in range(x, w):
if data[c, y] < 128: # black pixel
total_black += 1
else:
break
if total_black <= threshold: # if the number of black is small, set it to white
for c in range(total_black):
data[x + c, y] = 255
x += total_blackSo if your image’s row is like this ...#....####...##.#, with 3 line cross the row, the algorithm will remove all pixels at 1, 3 and 4: ........####........
Here is the result after rows removing: 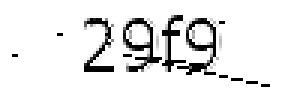 , and after columns removing:
, and after columns removing: 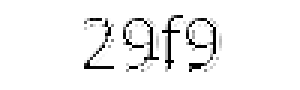
At this point, it’s already fairly accurate, just use Tesseract like normal. I tried all threshold and find the answer with 4 characters, but really you can just set threshold to 2 or 3 and it will work.
import pytesseract
for threshold in range(2,5):
res = pytesseract.image_to_string(Image.open('m1_convert.png'), config="-c tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyz0123456789")
if len(res) == 4:
print(res)
break
'29f9'2.Blur and average image
One of the other trick I learned is to blur the image and then average the black/white value of the current pixel (or really just check only the current pixel)
So, I run the captcha through two image filter. I found that 1 filter is not enough, and 3 is too much, but sometime 3 may help.
img = img.filter(ImageFilter.SMOOTH_MORE)
img = img.filter(ImageFilter.SMOOTH_MORE)Before (I tweaked the first algorithm so it leave a little line behind): 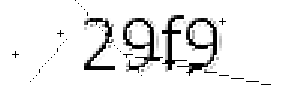
and After: 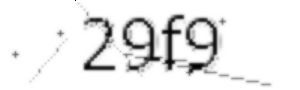
After that, I just check if the pixel’s value is more or less than 128, then set the value to 255 or 0 accordingly. It’s pretty easy, you may want to tweak the value to match your image, or just try from 100 to 200.
for x in range(w):
for y in range(h):
if img[x, y] < 128:
img[x, y] = 0
else:
img[x, y] = 255One thing I noticed is resize the image back to its original size after processing improves the success rate, downscale with HAMMING gave me the best result.
img = img.resize((w // 3, h // 3), Image.HAMMING)
imt.save('m1_processed.png')The result image is pretty good 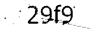 (threshold 2) and
(threshold 2) and 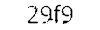 (threshold 3)
(threshold 3)
Improving
There’s more to improve, but it doesn’t really matter because Chungta.vn’s captcha is pretty weak. Here are things you can improve on:
- Detect plus sign and remove it. It’s pretty easy and effective since the first algorithm doesn’t remove it well.
- Detect the text area only: it’s also easy, just count the number of continuous black pixel per column.
- Average multiple result image with different threshold. Image what it’ll be like if you combine two final images above.
- Dilate and Erode: this is an interesting algorithm to remove edges and thickening text.
Closing
Preventing bot is a hard problem, but there are de-facto standard out there, so don’t reinvent the wheel. Use a good library or just use Google’s recaptcha. It’s good.
And also if you’re running a competition in your company, consider using your email’s user and password to validate user. Using a weak captcha is just asking for problems.